Disaster Recovery Definition
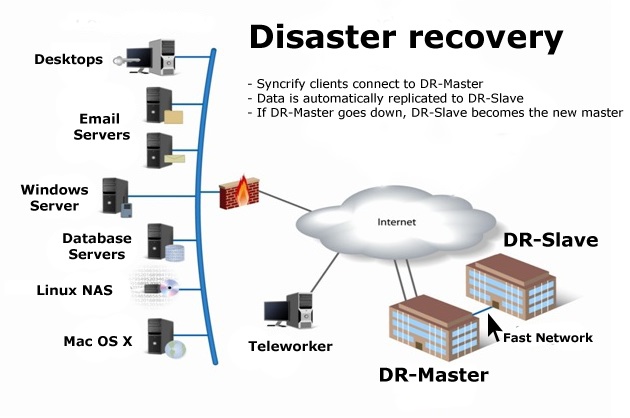
Disaster recovery (DR) is an area of security planning that aims to protect an organization from the effects of significant negative events. DR allows an organization to maintain or quickly resume mission-critical functions following a disaster.
A disaster can be anything that puts an organization’s operations at risk, from a cyberattack to equipment failures to natural disasters. The goal with DR is for a business to continue operating as close to normal as possible. The disaster recovery process includes planning and testing, and may involve a separate physical site for restoring operations.
The importance of disaster recovery: RPO and RTO
As businesses have become more reliant on high availability, the tolerance for downtime has decreased.
A disaster can have a devastating effect on a business. Studies have shown that many businesses fail after experiencing a significant data loss, but DR can help.
Recovery point objective (RPO) and recovery time objective (RTO) are two important measurements in disaster recovery and downtime.
RPO is the maximum age of files that an organization must recover from backup storage for normal operations to resume after a disaster. The recovery point objective determines the minimum frequency of backups. For example, if an organization has an RPO of four hours, the system must back up at least every four hours.
RTO is the maximum amount of time, following a disaster, for an organization to recover files from backup storage and resume normal operations. In other words, the recovery time objective is the maximum amount of downtime an organization can handle. If an organization has an RTO of two hours, it cannot be down for longer than that.
The RPO and RTO help administrators choose optimal disaster recovery strategies, technologies and procedures.
Meeting tighter RTO windows requires positioning secondary data so that it can be accessed faster. Recovery-in-place is one method of restoring data more quickly. This technology moves backup data to a live state on the backup appliance, eliminating the need to move data across a network. It can protect against storage system and server failure. Before using recovery-in-place, an organization needs to consider the performance of the disk backup appliance, the time needed to move data from a backup state to a live state, and failback. Since recovery-in-place can take up to 15 minutes, an organization may need to perform replication if it wants a quicker recovery time.
Preparing for a disaster requires a comprehensive approach that encompasses hardware and software, networking equipment, power, connectivity and testing that ensures DR is achievable within RTO and RPO targets. While implementing a thorough DR plan isn’t a small task, the potential benefits are significant.
Disaster recovery planning and strategy
A disaster recovery plan provides a structured approach for responding to unplanned incidents that threaten a company’s IT infrastructure, including hardware and software, networks, procedures and people.
The plan provides step-by-step disaster recovery strategies for recovering disrupted systems and networks to minimize negative impacts to company operations. A risk assessment identifies potential threats to the IT infrastructure; the DR plan outlines how to recover the elements that are most important to the company.
- A disaster recovery policy statement, plan overview and main goals of the plan.
- Key personnel and DR team contact information.
- Description of emergency response actions immediately following an incident.
- A diagram of the entire network and recovery site.
- Directions for how to reach the recovery site.
- A list of software and systems that will be used in the recovery.
- Sample templates for a variety of technology recoveries, including technical documentation from vendors.
- Tips for dealing with the media.
- Summary of insurance coverage.
- Proposed actions for dealing with financial and legal issues.
- Ready-to-use forms to help complete the plan.
According to Kirvan, the development team should include the following activities when creating their DR plan:
- Meet with the internal technology team and network administrator to establish the scope of the plan, and then brief senior management on the meeting.
- Gather all of the relevant network infrastructure documents.
- Identify the most serious threats and vulnerabilities to the infrastructure.
- Review the previous history of outages and disruptions and how the business handled them.
- Identify the most critical IT assets and determine their maximum outage time.
- Identify the emergency response team and its capabilities.
- Have management review the plan.
- Test the plan and update it if necessary.
- Schedule the next review/audit of disaster recovery capabilities.
An organization should consider its disaster recovery plan a living document. The DR plan needs scheduled reviews and updates to ensure it is accurate and will work if a recovery is required. The plan ahould also be updated whenever there are changes in the business that could affect disaster recovery.
Disaster recovery testing
Testing is critical to change management in DR planning, helping to identify gaps and providing a chance to rehearse actions in the event of a crisis. A DR plan has a lot of moving parts, so testing it can help the organization understand exactly what employees should be doing during disaster recovery scenarios.
- Secure management approval and funding for the test.
- Provide detailed information about the test.
- Make sure the entire test team is available on the planned test date.
- Ensure your test does not conflict with other scheduled tests or activities.
- Confirm test scripts are correct.
- Verify that the test environment is ready.
- Schedule a dry run of the test.
- Be ready to halt the test if needed.
- Have a scribe take notes.
- Complete an after-action report about what worked and what failed.
- Use the results from the test to update the DR plan.
While it is optimal to perform a comprehensive disaster recovery test, this may not always be possible because of a lack of funding, time or resources. In that case, an organization should still bring together the key participants, distribute all of the relevant documents and perform a walkthrough of the test. There are risks to this scaled-down DR testing approach, as technology that has not been thoroughly tested may not work properly when needed.
Cloud disaster recovery/Disaster recovery as a service
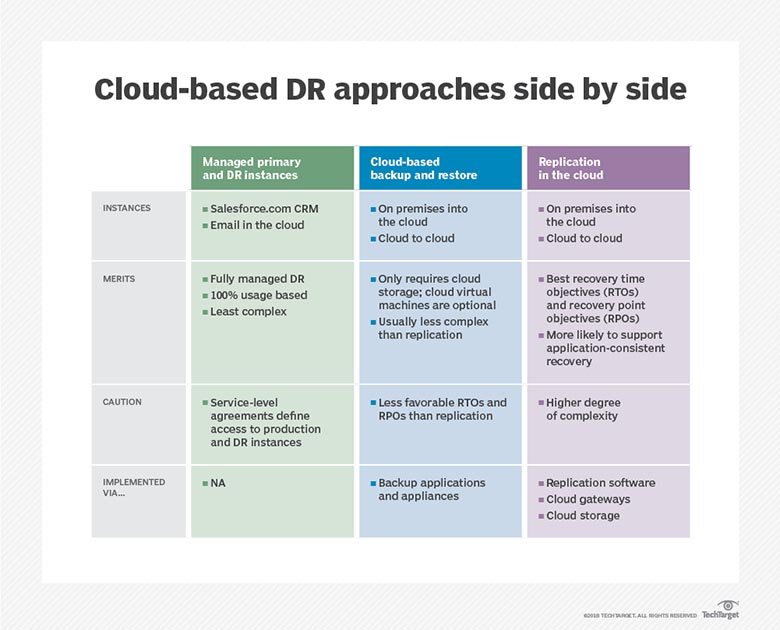
Disaster recovery as a service (DRaaS) is a cloud-based method of DR that has gained popularity in recent years.
Positives of DRaaS include lower cost, easier deployment and the ability to test plans regularly. Cloud services save a company money by running on a shared infrastructure. They are more flexible, as companies can sign up for just the services they need. DR tests can be completed by simply spinning up temporary instances.
But cloud-based disaster recovery may not be available after a large-scale disaster, as there may not be enough room at the DR site to run every DRaaS user’s applications. Cloud DR also increases bandwidth needs and could degrade network performance with more complex systems. Costs vary widely among vendors — some charge based on network bandwidth consumption or storage consumption — and can add up quickly.
Before choosing a provider, an organization should conduct an internal assessment to determine its disaster recovery needs. Questions to ask a potential DRaaS provider include:
- Will DR as a service work based on the existing infrastructure? How will the product integrate with existing backup and DR platforms?
- What percentage of the provider’s customers can be supported simultaneously during a regional disaster?
- What happens if the provider cannot supply a disaster recovery service?
- How will users access internal applications?
- How long can a customer run in the provider’s data center after a disaster? What are the failback procedures?
- How much help can be expected from the provider during a disaster?
- What is the process for testing?
- Does the product offer scalability?
- Exactly how does the provider charge for its disaster recovery service?
In most cloud recovery situations, an organization should plan on failing workloads back to the original location as soon as the crisis is resolved. However, some DRaaS providers do not support automated failback.
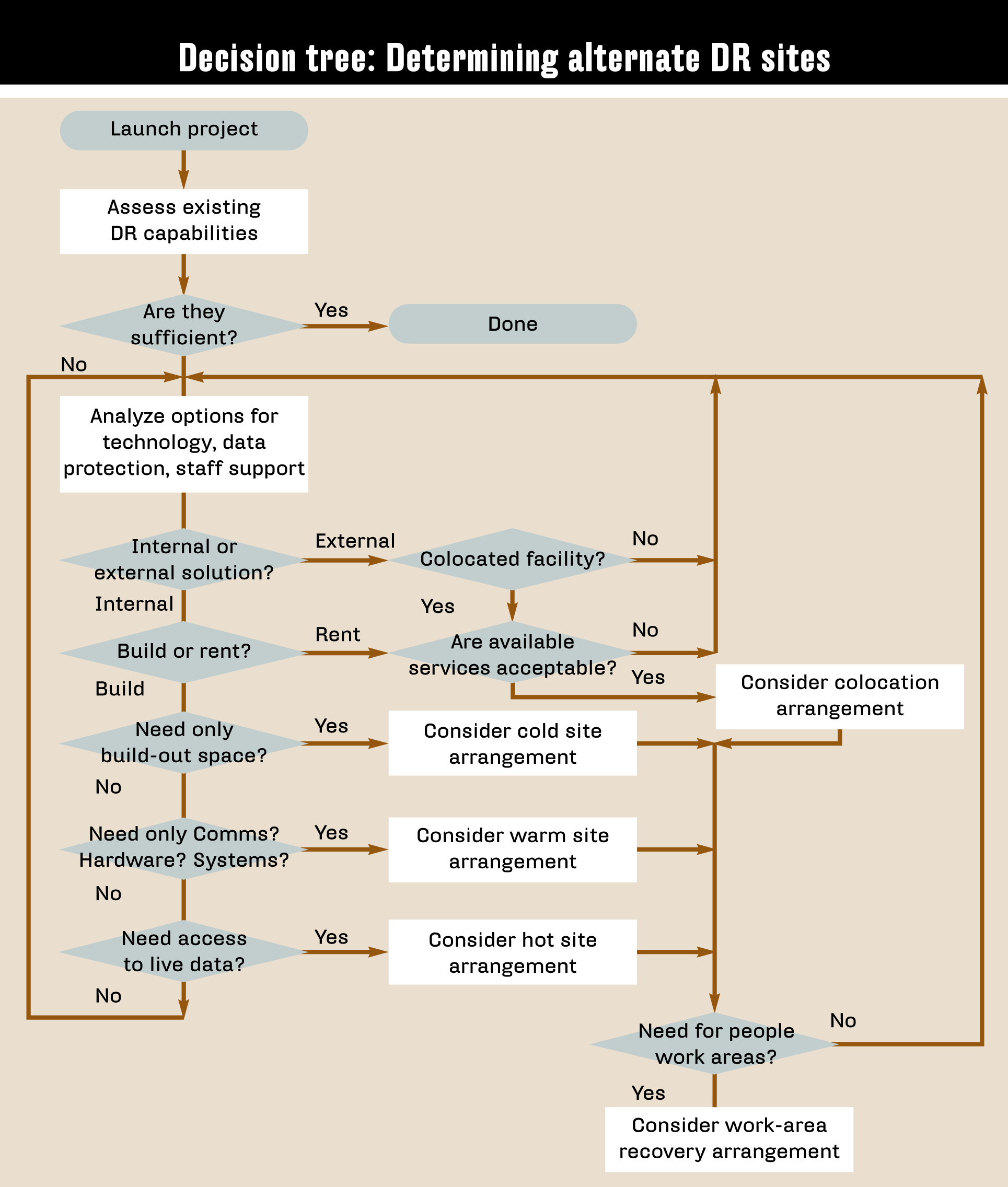
Disaster recovery sites: Hot, warm and cold
At a DR site, an organization can recover and restore its technology infrastructure and operations when its primary data center is unavailable. DR sites can be internal or external.
An organization sets up and maintains an internal disaster recovery site. Companies with large information requirements and aggressive RTOs are more likely to use an internal DR site, which is typically a second data center. Among the considerations in building an internal site are hardware configuration, supporting equipment, power maintenance, heating and cooling of the site, layout design, location and staff. An organization may want to perform a risk assessment of the recovery site as if it is the primary data center.
The internal site option is often much more expensive than an external site, but a major advantage is control over all aspects of the disaster recovery process.
An outside provider owns and operates an external disaster recovery site. External sites can be hot, warm or cold.
- Hot site: A fully functional data center with hardware and software, personnel and customer data, typically staffed around the clock; operationally ready in the event of a disaster.
- Warm site: An equipped data center that does not have customer data; an organization can install additional equipment and introduce customer data following a disaster.
- Cold site: Has infrastructure to support IT systems and data, but no technology until an organization activates DR plans and installs equipment; sometimes used to supplement hot and warm sites during a long-term disaster.
Distance is a key element of a disaster recovery site. A closer site is easier to manage, but it should be far enough away that it’s not impacted by a major disaster affecting the primary data center. Sites farther away may require more staff and drive up costs.
A cloud recovery site is another option. This method is cheaper and uses less company resources and infrastructure, but users need to be mindful of bandwidth and security.
Regarding sites, an organization should consider site proximity, internal and external resources, operational risks, service-level agreements and cost when contracting with disaster recovery service providers.
Tiers of DR
In the 1980s, the Share Technical Steering Committee, working with IBM, presented a description of disaster recovery service levels using tiers 0 through 6. Tier 0 represents the least amount of off-site recoverability and tier 6 represents the most.
- Tier 0: No off-site data. Recovery is only possible using on-site systems.
- Tier 1: Physical backup with a cold site. Data, likely on tape, is transported to an off-site facility that does not have the necessary hardware installed.
- Tier 2: Physical backup with a hot site. Data, likely on tape, is transported to an off-site facility that has the necessary hardware installed to support key systems of the primary site.
- Tier 3: Electronic vaulting. Data is electronically transmitted to a hot site.
- Tier 4: Point-in-time copies/active secondary site. Vital data is copied across the primary and secondary sites, each site backing up the other. Disk is often used in this tier.
- Tier 5: Two-site commit/transaction integrity. Data is continuously transmitted across sites.
- Tier 6: Minimal to zero data loss. Recovery is instantaneous, often involving disk mirroring or replication.
A tier 7 was later added to include automation, and it represents the highest level of availability in disaster recovery scenarios.
In general, while the ability to recover improves with the next highest tier, costs also increase.
Types of disasters
There is a wide range of disasters — caused by both humans and nature — that lead to recovery situations. A certain type of disaster may seem improbable, but it is important to recognize the possibility of it occurring for disaster recovery purposes.
Examples of types of disasters include:
- Application or virtual machine failure.
- Communication failure.
- Chassis failure, which can cause a single host or multiple hosts to fail.
- Rack failure.
- Data center disaster ranging from inadvertent triggering of a sprinkler system to a power failure to a flood or fire.
- Building disaster.
- Campus disaster; for example, a tornado that destroys one area.
- Citywide disaster.
- Regional disaster. Examples include Hurricane Katrina and Superstorm Sandy.
- National disaster. This is more likely in very small countries, but not impossible in larger nations.
Recognizing that these disasters exist is the first step in planning for them.